
The year 2025 is shaping up to be a defining moment for the global AI ecosystem. Every sector, from healthcare and research to finance and media, is depending on faster and more efficient access to GPU compute. This growing demand has made it essential for companies and individual users to understand GPU reservation plans, GPU cloud pricing, cloud credits, and the variety of GPU cloud plans available across the market. These four concepts have become the foundation of cost-efficient AI operations and are more important today than ever before.
As GPU availability fluctuates and prices shift based on global supply, choosing the right plan can determine whether an organisation saves money or overspends by a wide margin. This is why an in-depth understanding of reservation models, pricing structures, and credit systems matters. It is not just about renting a GPU anymore. It is about strategically selecting the right approach that fits your workload pattern, budget, and long-term project goals.
In this guide, you will learn how to break down the complexities of GPU reservation plans, interpret modern GPU cloud pricing systems, choose the right GPU cloud plans for different AI workloads, and make smart use of cloud credits to reduce total spend. You will also understand the financial logic behind each model, how to avoid common mistakes, and how to align your choice with your technical requirements.
This blog is written as a practical, step-by-step framework that anyone can use, whether you are a solo developer fine-tuning smaller models or a large enterprise deploying workloads for multimodal AI systems. By the end of this guide, you will have a clear understanding of what to choose, when to choose it, and how to predict your GPU spending with confidence.
What GPU Reservation Plans Really Mean in 2025
GPU reservation plans in 2025 are no longer simple time-based commitments. They represent a shift in how AI teams manage and forecast GPU requirements. Instead of relying on unpredictable on-demand availability, users can now reserve specific GPU models for defined time blocks such as a week, a month, a quarter, or even a full year. This allows complete control over availability, cost, and performance.
A GPU reservation plan gives guaranteed access to compute resources even during high demand periods. This guarantee is extremely valuable because AI workloads can be delayed or disrupted if GPUs suddenly become unavailable. These interruptions can slow down research cycles or delay production deployments. A reservation eliminates this uncertainty and creates a predictable operational environment.
More importantly, reservation models offer pricing benefits. When you commit to a fixed duration upfront, the GPU cloud provider can reduce overall cost because the resource allocation becomes more efficient at their end. This is why reserved instances typically cost significantly less than hourly on-demand instances. In many cases, long-term commitments can reduce your total.
GPU reservation plans in 2025 go far beyond the traditional concept of advance booking. They now represent a strategic financial model designed to optimise cost, ensure access to high-performance compute, and stabilise AI development timelines. Many organisations struggled in earlier years because GPU availability fluctuated during peak AI training seasons. As a result, reservation plans became the foundation of predictable GPU operations.
Why GPU Reservation Plans Matter
GPU reservations matter because they create a stable environment for long-running AI tasks. Modern AI projects often involve multi-week fine-tuning cycles, reinforcement learning setups, simulation-based generation, or continuous training loops for internal models. If the GPU becomes unavailable during these stages, the entire workflow must pause. This can increase total project duration, inflate costs, or even cause training resets.
With a reservation plan, users receive:
- Predictable access to GPUs even during periods of high global demand
- Lower long-term costs compared to on-demand hourly pricing
- More accurate budgeting and financial control
- Reduced operational risk for mission-critical AI pipelines
- Freedom from sudden price spikes or hardware shortages
How Reservation Plans Work in 2025
Although every cloud provider structures reservation plans differently, the underlying idea is similar. Users commit to a specific GPU type, a duration, and a pricing structure. Once the reservation is confirmed, the GPU remains fully accessible for the entire period without interruption.
A typical reservation workflow includes the following steps:
- Selecting the GPU model, such as H100, H200, GH200, A100, or L40S.
- Choosing the reservation duration, such as one week, one month, one quarter, six months, or a full year.
- Reviewing the discounted pricing compared to standard GPU cloud pricing.
- Confirming hardware availability in the relevant region.
- Making payment or applying available cloud credits.
- Accessing the GPU environment immediately or at the scheduled start time.
Reservation vs On-Demand Pricing Overview
The table below summarises the typical differences between reservations and on-demand pricing. These are industry-wide patterns and not specific to any single provider.
| Factor | GPU Reservation Plan | On-Demand Plan |
|---|---|---|
| Price per hour | Lower due to commitment | Higher due to flexibility |
| Availability | Guaranteed | Not guaranteed during peak periods |
| Budget predictability | Strong | Moderate or weak |
| Ideal use case | Long AI training jobs | Short or unpredictable jobs |
| Ability to extend | Allowed by some providers | Always allowed |
| Total cost efficiency | High | Low for long projects |
This comparison helps clarify why many AI teams shift to reservation-based approaches once their workload becomes stable or repeatable.
How Reservation Plans Affect GPU Cloud Pricing
GPU cloud pricing is heavily influenced by how much risk the provider takes on. When a customer uses on-demand billing, the provider must keep GPUs available without knowing whether they will be fully utilised. This uncertainty increases cost. When customers switch to GPU reservation plans, the provider can plan its hardware allocation more efficiently, which reduces cost. This is why reservation prices are consistently lower.
The relationship between pricing and reservation commitment is straightforward. The longer the duration, the lower the effective hourly price. Many providers offer tiered structures where a weekly reservation provides a small discount, a monthly reservation provides a moderate one, and a multi-month or yearly reservation provides the deepest savings.
How Reservation Plans Support GPU Cloud Plans
GPU cloud plans are the broader collections of compute options offered by a cloud provider. These plans include choices based on GPU model, RAM configuration, storage speed, network bandwidth, and deployment environment. Reservation plans act as a cost optimisation layer on top of these offerings. Instead of paying high on-demand GPU cloud pricing for these plans, users can apply reservation logic to access the same configurations at a lower cost.
If you think of GPU cloud plans as the menu, then reservation plans are the discount programme that helps you purchase from that menu more strategically.
Why Reservation Strategy Is Essential for AI Teams in 2025
The year 2025 represents a turning point because AI workloads are becoming larger and more complex. Models are now multimodal, memory intensive, and network heavy. Training windows are longer. Dataset sizes are bigger. Many companies are moving from experimentation to production grade AI systems. These shifts make cost efficiency and hardware reliability essential.
Problems AI Teams Faced Before Reservation Models Became Popular
Before modern reservation systems, teams often dealt with:
- Frequent GPU unavailability when global demand spiked
- Unpredictable monthly spending due to fluctuating billing
- Higher costs because they relied only on on-demand instances
- Delays in development cycles when GPUs ran out of capacity
- Difficulty planning budgets for quarters or fiscal years
GPU reservation plans solve all of these issues by offering guaranteed access and stable pricing.
The Financial Logic Behind Reservation Commitment
There is a simple economic principle behind reservation-based GPU cloud pricing. When you commit resources in advance, the provider reduces uncertainty and can optimise infrastructure. This operational stability allows them to offer meaningful savings. Whether you are a startup training foundational models or a researcher experimenting with reinforcement learning, reservation plans help reduce total cost of ownership.
Here is the financial impact in simple terms:
- On-demand pricing is high because the provider takes on maximum uncertainty.
- Reservation pricing is lower because uncertainty shifts from provider to user.
- Long-duration reservations create predictable revenue for the provider, which leads to even bigger discounts.
Where Cloud Credits Fit Into Reservation Planning
Cloud credits add another layer of financial efficiency. Cloud credits are pre-allocated funds or discount tokens that reduce the cost of GPU usage. They can be applied toward both on-demand and reservation models depending on provider rules. Users often receive cloud credits through promotions, sign-up bonuses, partnership programmes, hackathons, or enterprise agreements.
Cloud credits provide benefits such as:
- Reducing upfront cost when purchasing reservation plans
- Lowering monthly bills for long training cycles
- Making it easier to experiment without committing large budgets
- Helping startups manage expenses during early development
Cloud credits act as a cost buffer that can support your broader GPU reservation strategy.
Understanding the Architecture Behind High-Performance GPUs
To make an informed decision while comparing GPU cloud providers, understanding the architecture and performance behavior of modern GPUs becomes essential. Whether the goal is large-scale generative AI training, high-throughput inference, or fine-grained model experimentation, the underlying architectural features determine both efficiency and cost.

How Modern GPU Architecture Impacts Performance
Modern GPUs such as the NVIDIA A100, H100, L40S, and RTX 4090 rely on several architectural pillars that define their capabilities. These include streaming multiprocessors, specialized tensor cores, high bandwidth memory, and dedicated interconnect systems.
Key Architectural Components Explained
1. Streaming Multiprocessors
These are the core computational blocks of a GPU. More SMs typically result in higher parallelism and improved performance for deep learning workloads. For example, the H100 contains significantly more SM clusters than the A100, allowing it to deliver faster training throughput.
2. Tensor Cores
Tensor cores accelerate matrix operations, which are fundamental to neural network training and inference. Modern tensor cores support a wide range of precision modes including FP16, BF16, FP8, and INT8. This allows teams to balance speed, accuracy, and cost based on their workloads.
3. High Bandwidth Memory
HBM2e and HBM3 provide extremely fast data transfer speeds between the memory banks and compute units. Faster memory helps models process larger batches without bottlenecks, making GPUs with higher HBM bandwidth more suitable for large language model training.
4. GPU Interconnect Systems
Training large models across multiple GPUs requires fast communication links. Technologies like NVLink, NVSwitch, and PCIe Gen5 reduce communication overhead, improving scalability. H100 clusters with NVLink provide significantly lower latency than clusters without such interconnects.
Architectural Differences Across Popular GPUs
| GPU Model | Memory Type | Tensor Core Support | Interconnect Availability | Ideal Use Case |
|---|---|---|---|---|
| NVIDIA A100 | HBM2e | FP16, BF16, TF32, INT8 | NVLink available | Large model training and enterprise AI workloads |
| NVIDIA H100 | HBM3 | FP8, BF16, FP16, INT8 | NVLink and NVSwitch | Advanced LLM training and high-performance compute |
| NVIDIA L40S | GDDR6 | FP16, BF16, INT8 | PCIe based | Inference at scale and medium-size model training |
| RTX 4090 | GDDR6X | FP16, FP32, INT8 | PCIe based | Fine-tuning, research experimentation, and low-cost training |
This table helps illustrate why GPU cloud providers in the USA offer varied pricing models. Each GPU architecture addresses different needs, and the selection profoundly affects performance and budget planning.
Why Architectural Fit Matters When Choosing a GPU Provider
Selecting the optimal GPU cloud provider depends on matching the GPU architecture with your workload characteristics. For example:
- Large-scale generative AI training benefits from H100 or A100 clusters with fast interconnects.
- Inference heavy setups require GPUs like L40S due to their optimized performance per watt.
- Budget conscious researchers often find RTX 4090 based providers highly efficient for small and medium workloads.
When evaluating GPU cloud providers in the USA, the alignment of architecture with business needs can help maximize both performance and cost efficiency. The correct match saves time, reduces compute waste, accelerates iteration cycles, and ensures scalability as model sizes grow.
A Detailed Comparison of GPU Cloud Pricing Models and How Reservation Plans Reduce Costs
Understanding how GPU cloud pricing works is essential when choosing between GPU reservation plans, GPU cloud pricing tiers, and cloud credits. The market is crowded with different pricing approaches, so comparing them clearly helps you identify which GPU cloud plan fits your technical and financial requirements. This section explains the major pricing models used by top GPU cloud providers and then moves into a structured analysis of the featured offers available from Dataoorts. The focus is on how these models influence long-term cost, performance stability, and resource predictability.
Common Pricing Models in GPU Cloud Infrastructure
Cloud providers use several pricing structures, each suited to a different type of workload.
On-demand pricing
This model charges you per hour or per minute based on actual GPU consumption. It provides maximum flexibility because you can start or stop GPUs at any time. It is suitable for exploratory experiments, quick tests, and unpredictable workloads. The trade-off is that on-demand rates are generally the highest because providers must maintain spare capacity.
Reservation-based pricing
This model involves committing to a GPU or cluster for a fixed duration such as a week, a month, or several months. Providers reward the commitment with significant discounts, which makes the effective hourly rate much lower than on-demand. It is ideal for teams running frequent training jobs or long-running production models. Reservation plans also ensure resource availability during peak demand periods.
Spot or preemptible pricing
This model offers unused GPUs at a deeply reduced cost. It is suitable for workloads that can tolerate interruptions, such as non-critical training runs or distributed experiments with checkpointing. The limitation is that the provider can take back the GPU when demand increases, so the workload must be resilient.
Credit-based pricing
Cloud credits allow users to pre-purchase or receive allocated funds that can be applied against GPU usage. Credits may come from startup programs, promotional grants, or enterprise bundles. Using credits effectively can drop the overall cost considerably, especially when paired with reservation deals.
Dataoorts Offers and How They Work
In the middle of your planning process, it is important to evaluate the reservation and discount structures offered by Dataoorts. The Dataoorts “Featured Offers” page lists several GPU cloud plans that focus on predictable performance, cost efficiency, and flexible commitment periods. These offers are designed for teams that prefer stability and do not want to risk resource unavailability during peak demand.
Key characteristics of Dataoorts offers include:
- Flexible commitment periods so that users can choose a reservation duration that matches the workload.
- Availability of multiple GPU models across both virtual machines and bare metal servers, allowing teams to align performance needs with budget limits.
- Support for cloud credits, which can be applied directly to reduce reservation costs.
- A dynamic pricing architecture that ensures users are billed at an optimized rate based on actual resource efficiency and cluster availability.
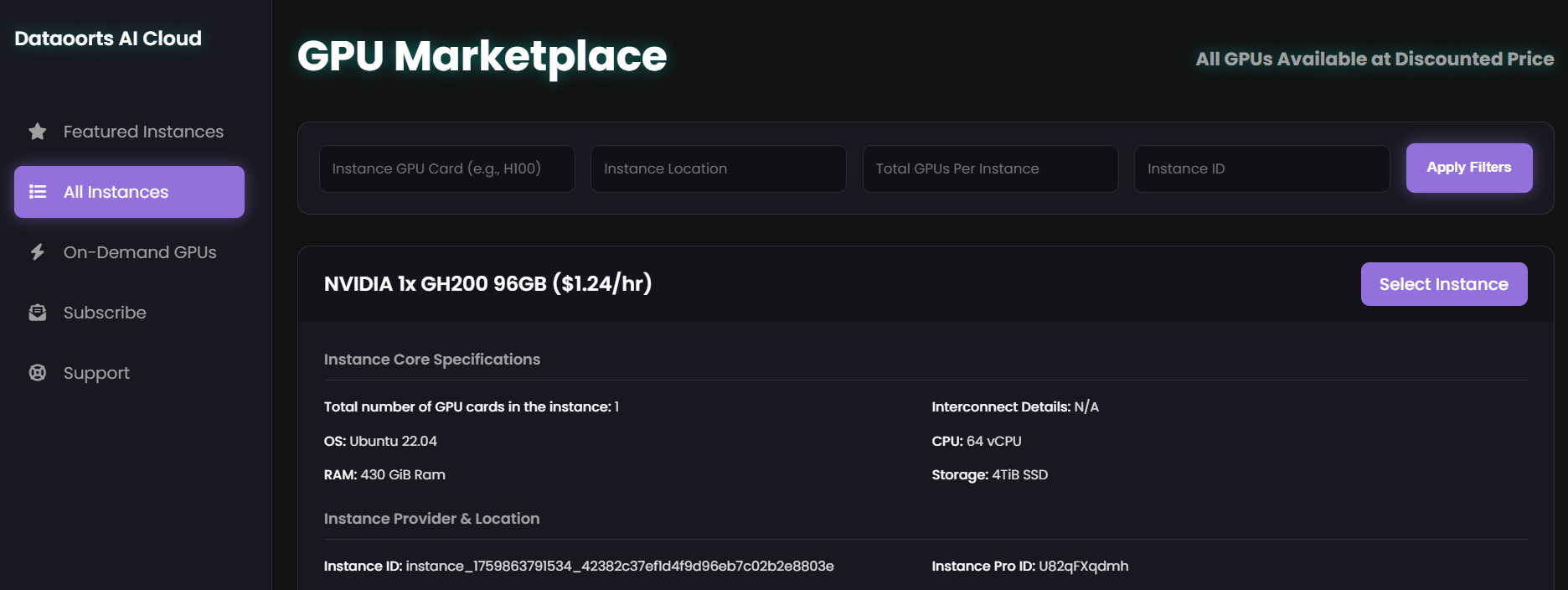
GPU Reservation Plans & Structures
Below is an example of how different reservation options typically compare. This table is illustrative and should be considered a structural guide rather than live pricing.
| GPU Model | Reservation Duration | Approximate Discount vs On-Demand | Best Use Case |
|---|---|---|---|
| H100 VM | 1 month | 30 to 45 percent | Frequent fine-tuning, continuous experiments |
| H200 Bare Metal | 6 months | 50 to 60 percent | High-performance training and large-scale LLM workloads |
| A100 VM | 3 months | Around 40 percent | Research workflows, generative model training |
| L40S VM | 1 week | Around 20 percent | Short-term testing and rapid prototyping |
Making the Most of Dataoorts GPU Reservation Plans
To maximize the advantage of reservation-based GPU cloud plans, consider the following best practices:
- Assess your training requirements and estimate the number of GPU hours needed for each project stage.
- Select a GPU model that aligns with your actual performance needs rather than defaulting to the most expensive option.
- Choose reservation durations that mirror your workload stability. Shorter commitments suit experimentation, while longer terms benefit production models.
- Apply cloud credits strategically by using them on high-cost GPUs or long reservation periods to reduce billing impact.
- Monitor GPU utilization throughout the reservation to ensure you are getting full value and adjust future reservations accordingly.
- Understand the modification and renewal policies so that your plan remains flexible as your project scope evolves.
Balancing Predictability and Flexibility
Reservation plans provide consistent performance and predictable pricing. However, flexibility remains an important factor. Many teams combine a small pool of on-demand GPUs with a long-term reservation to handle sudden workload spikes without overcommitting financially. This hybrid approach ensures stability through reservation while still responding quickly to new operational demands.
Cost Predictability and Long-Term Planning
One of the strongest advantages of choosing a GPU reservation plan is the stability it brings to long-term budgeting. On-demand GPU usage tends to fluctuate significantly, which makes it difficult for teams to forecast monthly or quarterly cloud expenses. Reservation-based pricing establishes a fixed cost for a defined period, allowing engineering and finance teams to work with predictable numbers.
This predictability has practical impacts on the workflow. Training cycles can be scheduled confidently without fearing unexpected charges. Large model retraining becomes easier to automate, and multi-stage pipelines can run continuously without having to pause or shut down instances. When you know a GPU is reserved exclusively for your workload, operational stress decreases and development timelines become more reliable.
Performance Stability With Reserved GPUs
Reserved GPUs also deliver higher performance reliability compared to spot or preemptible options. Interruptions on spot GPUs can break multi-day training runs, especially when working with LLMs or multimodal models. Reserved capacity, however, remains available throughout the commitment period. This ensures smooth execution for reinforcement learning, distributed training frameworks like DeepSpeed, and fine-tuning processes that depend on stable compute availability.
The absence of sudden evictions or capacity shortages means your models train more efficiently. This leads to fewer restarts, fewer checkpoints, and better overall productivity, especially for teams managing complex pipelines.
Making Cloud Credits Work With GPU Cloud Plans
Cloud credits further enhance the value of a reservation strategy. Whether provided through startup programs, enterprise partnerships, or promotional offers, credits directly reduce the cost of GPU consumption. They are especially useful when a team is still evaluating which GPU model suits their workload or when early experimentation requires additional flexibility.
When paired with a reservation plan, cloud credits can significantly lower the effective cost of ownership. They are particularly beneficial for research labs, early-stage AI companies, and independent developers who need to stretch their compute budget without compromising on access to powerful GPUs.
Evaluating Providers Beyond Just the Price Tag
Price alone should not be the deciding factor when choosing a GPU cloud plan. Performance consistency, hardware quality, storage throughput, network speed, and customer support all influence the real-world efficiency of your AI workflow. Dedicated GPUs often deliver better performance than virtualized ones, and a well-designed dashboard with clear monitoring tools can save hours of troubleshooting.
Dataoorts is among the platforms that combine competitive pricing with operational stability. Their featured offers include multiple GPU models, flexible reservation durations, and support for cloud credits, making it easier for teams to match their budget with their workload. Beyond the discounts, the emphasis on reliability and straightforward provisioning helps ensure that developers experience fewer interruptions during critical training cycles.
Strategic Framework for Selecting the Best GPU Reservation Plan in 2025
Choosing the right GPU reservation plan is not a simple matter of comparing prices or listing GPU models. As AI deployments become more complex and training cycles grow longer, organizations require a more structured, strategic approach. A reservation plan must align with the model roadmap, experiment velocity, team size, scalability requirements, and budget projections. This section provides a comprehensive framework for making that decision in a way that blends technical understanding with financial clarity.
Start With Your Workload Profile
Every team has a different workload pattern, and identifying that pattern early helps prevent unnecessary spending. Workloads tend to fall into three broad categories:
Continuous training workloads
Teams working on large-scale models or frequent retraining cycles require GPUs almost every day. If your training pipelines run more days than they pause, a long-term reservation is always more economical. These teams usually benefit from 3-month, 6-month, or even yearly commitments.
Burst-based workloads
Some teams run heavy compute for a short period, then scale down for a few weeks. These include hackathons, field experiments, minor fine-tuning rounds, or small research teams that only train models after collecting new datasets. Their usage fluctuates but still requires reliability when active. Short-term reservations like 1 week or 1 month fit this profile.
Exploration-heavy workloads
These are teams in the early stages of model building, architecture search, or dataset preparation. They are still determining which model to pursue long term. They need flexibility more than predictability, so on-demand GPUs or short-term reservations are better until they finalize their training pipeline.
Understanding where your team falls in this spectrum prevents overbuying or underbuying. This directly influences GPU selection, reservation duration, and credit allocation.
Identify the Right GPU for Your Model Size
Choosing a GPU is not just about power; it is about proportionality. An oversized GPU wastes budget if your model does not require it, while an undersized GPU slows your training drastically.
Small and mid-sized models
Models under 10B parameters (instruction-tuned LLMs, diffusion fine-tuning, vision transformers) often perform optimally on A100, L40S, or similar GPUs. These are often available at lower reservation cost.
Large language models and multimodal systems
Models above 20B parameters benefit from H100 or H200 architecture because of higher memory bandwidth and improved tensor core performance. These are more expensive but reduce training time significantly.
Inference-first pipelines
Products built around serving multiple simultaneous inference requests require GPUs with high throughput rather than memory size. L40S and A10 GPUs often excel here.
A carefully chosen GPU ensures that a reservation plan is both cost-efficient and performance aligned.
Map Reservation Length to Project Timeline
Many teams make the mistake of choosing a reservation term without thinking through the duration of their project phases. A more effective approach is to break your workflow into three segments:
- Experimentation and prototyping
This phase requires flexibility because the architecture is still evolving. A short-term reservation helps maintain control without unnecessary commitment. - Training and fine-tuning phase
This is the heaviest compute segment. Once your architecture stabilizes, a 3-month or 6-month reservation is ideal. Costs drop significantly, and stability becomes more important than flexibility. - Deployment and scaling
If inference demand is stable, a longer reservation ensures predictable cost. If demand fluctuates, mixing on-demand GPUs with a smaller reserved baseline offers both stability and elasticity.
The length of the reservation should always reflect where your project currently stands, not where it was six months ago.
Understand Hidden Costs Beyond GPU Pricing
One major oversight many teams make when comparing GPU cloud plans is ignoring ancillary costs. Providers differ significantly in how they price storage, networking, data transfer, and orchestration.
Some hidden costs to evaluate include:
- Storage charges for training datasets, checkpoints, and logs
- Egress fees when exporting models or results
- Network charges for multi-GPU distributed training
- API usage fees for orchestration or autoscaling
- Premiums for bare-metal provisioning
When analyzing GPU reservation plans, it is important to compare the total cost of ownership, not just the GPU hourly rate. Providers like Dataoorts optimize several of these backend charges, which gives them an edge when scaling long-term workloads.
Assess Scalability Needs Before Committing
A GPU reservation plan is only as good as its ability to handle sudden spikes or unexpected changes. If your plan is too rigid, you may face situations where your GPUs are fully occupied while your workload increases. A more adaptive strategy allows mixing reserved GPUs with on-demand units during peak weeks.
Scalability considerations include:
- Whether you anticipate running larger models in the next 6 months
- Whether your dataset size will grow significantly
- Whether you plan to run multi-GPU distributed training
- Whether you require redundancy to avoid downtime
A scalable reservation strategy prevents bottlenecks that delay product releases or research progress.
The Importance of Monitoring, Logging, and Utilization Analysis
Reserving a GPU does not guarantee efficiency. Teams that fail to monitor utilization often lose money without realizing it.
Key practices include:
- Tracking GPU utilization percentages daily
- Observing idle periods and identifying patterns
- Analyzing how much of the reserved capacity is actually being used
- Building automated workflows that shut down unused processes
- Regularly reviewing whether the reservation plan matches new workload patterns
An underutilized reservation is more expensive than on-demand usage. Continuous monitoring ensures you only commit to what you truly need.
Security and Compliance Factors in GPU Cloud Plans
With stricter global regulations around data governance, security must be part of the reservation decision. This is often overlooked when teams focus heavily on pricing.
Some factors to consider:
- Where your data is stored and processed (regional compliance)
- Whether your provider supports private networking or isolated clusters
- Encryption standards for data at rest and in transit
- SLA commitments for downtime and incidents
- Compliance readiness for ISO, SOC 2, HIPAA, and GDPR
Providers like Dataoorts offer strong compliance support, which is especially important for enterprise and regulated-sector teams.
Why Teams Are Shifting Toward Long-Term Reservation Strategies
In 2025, AI infrastructure is evolving fast. The demand for GPUs is rising faster than supply, creating unpredictable availability across multiple platforms. This makes reservation plans not just a cost-saving tactic but also a strategic necessity.
The shift to reservation is driven by:
- Higher training frequency due to model updates
- Larger models requiring stable, uninterrupted compute
- Growth in commercial AI applications
- Increasing GPU shortages in peak seasons
- The need to control cloud expenditure amid scale
Teams adopting reservation plans early secure priority access to premium hardware and ensure long-term project stability.
Integrating Reservation Plans Into Organizational Strategy
The biggest change happening in AI teams today is the shift from GPU planning being an engineering decision to being an organizational one. Finance teams, product teams, and leadership are now directly involved in decisions regarding GPU procurement and reservation strategies.
GPU reservations influence:
- Quarterly financial planning
- Delivery timelines
- Hiring decisions for ML engineers
- Model update frequency
- Product release cycles
- Scalability roadmap
A well-structured reservation plan becomes a core pillar of the organization’s AI strategy.
Choosing the Right GPU Reservation Strategy for 2025
As the demand for GPU compute rises globally, choosing the right GPU reservation plan becomes a crucial part of any AI strategy. Reservation-based pricing provides cost stability, guaranteed availability, and predictable performance, three factors that are now essential for efficient training and deployment of modern AI systems. Cloud credits further enhance this approach, giving teams additional financial flexibility and helping them reduce long-term expenditure.
In contrast, relying solely on on-demand or spot GPUs can introduce uncertainty. Interruptions, fluctuating costs, and inconsistent availability can slow down critical development cycles. A well-planned reservation strategy solves these issues by securing the exact compute resources you need, for the duration you need them, at a significantly lower effective cost.
Providers that offer optimized reservation plans, such as those found in the Dataoorts featured offers, are shaping the way teams approach infrastructure planning. With flexible commitment periods, multiple GPU models, and the ability to integrate cloud credits, teams can tailor their GPU cloud plans to match their workload patterns more precisely.
Building a sustainable and cost-efficient AI development pipeline is no longer just about raw compute power. It is about choosing the right combination of pricing structure, reservation model, and credit utilization. Teams that put this strategy in place today will have a competitive edge in both cost performance and execution speed throughout 2025 and beyond.
