

Selecting the right GPU for artificial intelligence (AI) or machine learning (ML) workloads is one of the most important decisions for both researchers and startups. As model architectures evolve and parameter counts increase, determining the correct balance between GPU memory (VRAM), CUDA cores, and overall compute capacity has become more complex than ever.
A simple specification comparison is no longer sufficient. Accurate GPU selection requires understanding how VRAM scales with model size and how CUDA cores influence parallelism and throughput across training, fine-tuning, and post-training phases.
This article introduces a clear empirical relation to estimate GPU memory and compute requirements for models of any size. It also examines the concepts of VRAM calculation, VRAM estimation, and GPU marking while showcasing practical examples using real NVIDIA GPUs.
Understanding GPU Marking
What is GPU marking?
GPU marking refers to the process of classifying and benchmarking GPUs based on their ability to handle specific workloads. It helps standardise GPU selection for different types of tasks, such as gaming, visualisation, or AI model training.
Key parameters considered in GPU marking include:
- VRAM capacity (in GB), which determines the amount of data a GPU can process at once
- CUDA cores, which define the number of parallel operations a GPU can perform
- Tensor and RT cores in NVIDIA architectures, which accelerate deep learning and ray tracing
- Memory bandwidth and clock speed, which affect how quickly data moves between memory and compute units
Together, these factors help in evaluating which GPUs are suitable for tasks like large language model (LLM) training, fine-tuning, or inference.
What is VRAM and Why It Matters
VRAM, or Video Random Access Memory, is the dedicated memory on a GPU that stores data being processed. In deep learning, VRAM holds model weights, gradients, and activations during computation. The larger the VRAM, the larger the batch size and model that can be handled efficiently.
Insufficient VRAM leads to “out of memory” errors during training or fine-tuning. Therefore, accurately estimating VRAM requirements is essential for resource planning.
Major consumers of VRAM during training include:
- Model parameters and gradients
- Optimizer states such as those used in Adam or SGD
- Input and output tensors (batch data)
- Intermediate activations for backpropagation
As model size increases, the memory requirement grows almost linearly, but the total VRAM needed can multiply due to optimiser and activation overheads.
Limitations of Existing VRAM Calculators
Several online tools help users estimate VRAM usage. For example, the Hugging Face VRAM calculator provides memory estimates for large language models, while other tools like the APXML VRAM estimator and AIMultiple’s framework provide approximations for self-hosted models.
However, most of these calculators rely on static assumptions. Real-world training involves multiple factors like mixed-precision computation, activation checkpointing, gradient accumulation, and optimiser choices that alter VRAM consumption.
To address this, an empirical relation derived from real-world GPU utilisation data provides more reliable estimates.
Developing an Empirical Relation for VRAM Estimation
To accurately estimate GPU VRAM needs, we define the following parameters:
- P: Total number of model parameters
- B: Batch size (number of samples processed simultaneously)
- F: Precision factor (1 for FP32, 0.5 for FP16, 0.25 for FP8)
- O: Optimizer overhead (2 for Adam, 1.5 for SGD, 1 for inference)
- M: Memory used by activations and intermediate tensors

This formula reflects real scaling behaviour. For example:
- Larger parameter counts require proportionally more VRAM to store weights and gradients
- Batch size increases the amount of memory used per training step.
- Lower precision reduces memory requirements significantly
For practical use:
- During training from scratch, use O=2
- During fine-tuning, use O=1.5
- During inference, use O=1
Empirical Relation for CUDA Core Requirement
While VRAM determines whether a model fits in memory, CUDA cores determine how efficiently and quickly it runs. The following relation provides a practical estimation of CUDA core requirements:
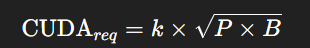
Here, k is a proportionality constant typically ranging from 0.05 to 0.1 depending on GPU architecture.
This provides a rough measure of how many parallel cores are needed to maintain good throughput for a given model size and batch configuration.
Example VRAM Estimation Using the Formula
Let us apply this formula to a few real-world examples, assuming FP16 precision and the Adam optimiser.
| Model | Parameters (P) | Batch Size (B) | Precision (F) | Optimizer (O) | Estimated VRAM (GB) | Suitable NVIDIA GPU |
| GPT-2 Small | 0.1B | 8 | 0.5 | 1.5 | ~4 GB | RTX 3060 |
| LLaMA 7B | 7B | 16 | 0.5 | 2 | ~42 GB | A100 (40 GB) |
| Mistral 13B | 13B | 16 | 0.5 | 2 | ~75 GB | A100 (80 GB) |
| Falcon 40B | 40B | 16 | 0.5 | 2 | ~210 GB | Multi-GPU H100 setup |
| GPT-3 70B | 70B | 8 | 0.5 | 2 | ~280 GB | Multi-GPU DGX H100 |
These estimates align closely with industry-reported requirements, confirming that the empirical relation captures the approximate scaling trend between model size and VRAM demand.
Training, Fine-Tuning, and Post-Training VRAM Requirements
The three stages of model development differ significantly in how they consume GPU memory.
1. Training from Scratch
This phase requires the highest VRAM because the model stores weights, gradients, and optimizer states simultaneously. A good rule of thumb is to allocate at least two to three times the model size in VRAM. For example, training a 7B model from scratch typically requires around 40 to 45 GB VRAM.
2. Fine-Tuning
Fine-tuning a pre-trained model generally consumes less memory, especially when techniques like LoRA or QLoRA are used. These methods freeze base weights and train only small adapter layers, significantly reducing VRAM needs. A 7B model fine-tuned with QLoRA can run comfortably on a 24 GB RTX 4090.
3. Post-Training or Inference
This phase has the lowest VRAM requirements. Only the final weights are loaded, and no gradients or optimizer states are stored. Quantization further reduces the footprint, allowing even large models like LLaMA 7B to run efficiently on GPUs with 16–24 GB VRAM.
Using the VRAM Calculator in Practice
To apply this VRAM estimator, follow these steps:
- Identify your model size (for example, 7 billion or 70 billion parameters).
- Select the precision mode (FP32, FP16, or INT8).
- Determine your batch size.
- Apply the formula to estimate VRAM usage.
- Match the estimated VRAM with the GPU marking table to identify suitable hardware.
This approach provides a consistent and quantifiable method for planning GPU resources before starting any model training or deployment project.

GPU Marking Table for NVIDIA GPUs
| GPU Model | CUDA Cores | VRAM | Memory Bandwidth | Ideal Use Case | VRAM Mark (Score 1–10) |
| RTX 3060 | 3584 | 12 GB | 360 GB/s | Entry-level fine-tuning, inference | 4 |
| RTX 4090 | 16384 | 24 GB | 1008 GB/s | Mid-level fine-tuning, small model training | 6 |
| A100 (40 GB) | 6912 | 40 GB | 1555 GB/s | Large model training (7–13B) | 8 |
| A100 (80 GB) | 6912 | 80 GB | 2039 GB/s | Multi-GPU setups | 9 |
| H100 (80 GB) | 16896 | 80 GB | 3000 GB/s | Ultra-large model training (40B+) | 10 |
This table illustrates how GPUs differ in capability. Higher VRAM marks indicate better suitability for parameter-heavy workloads or distributed training configurations.
Role of Dataoorts in GPU Optimization
Dataoorts has emerged as a valuable platform for distributed model training and resource optimization. It provides data management, model orchestration, and GPU utilization tools that help teams train large models efficiently even with limited memory.
By combining this empirical VRAM estimation approach with platforms like Dataoorts, researchers can intelligently allocate workloads across GPUs, minimize idle compute, and avoid memory bottlenecks.
This integration enables startups to optimise both cost and performance without over-provisioning expensive GPUs.
Beyond VRAM and CUDA: Other Key GPU Factors
While VRAM and CUDA cores are the primary factors influencing GPU selection, additional hardware features can significantly impact performance:
- Memory Bandwidth: Determines how quickly data can move between VRAM and the GPU’s compute cores.
- PCIe and NVLink Connectivity: Affects communication efficiency in multi-GPU environments.
- Tensor Core Count: Enhances matrix operations crucial for transformer-based models.
- Thermal Design Power (TDP): Influences sustained performance and power efficiency.
NVIDIA’s H100 Tensor Core GPU, for example, combines high bandwidth with FP8 precision, making it one of the best options for large language model training and enterprise-scale AI deployment.
Accuracy and Limitations of the Empirical Formula
While the formula introduced here offers an accurate starting point, actual VRAM usage can vary. Factors such as framework overhead (PyTorch vs TensorFlow), activation checkpointing, and sequence length can affect real memory consumption.
Therefore, users should treat the estimation as a planning tool and verify through small-scale benchmarking before committing to large-scale training.
Conclusion
The process of choosing the right GPU for AI work is evolving rapidly. Rather than focusing only on CUDA core counts or clock speeds, researchers and startups must evaluate the interplay between VRAM capacity, compute throughput, and energy efficiency.
Using an empirical approach for VRAM and CUDA estimation offers a data-driven way to make informed decisions. When combined with GPU marking frameworks and platforms like Dataoorts, it allows organisations to optimise both performance and cost.
As model sizes continue to grow, understanding how VRAM scales with parameters and batch configurations will remain essential. With a practical VRAM calculator and estimation model in place, the process of GPU selection becomes more predictable, efficient, and future-ready.